Dominique Cardon compare l’apparition du numérique avec l’invention de l’imprimerie : un changement technique tel, qu’il impacte tous les pans de la société. Il s’agit là d’une rupture majeure dans la façon dont « nos sociétés produisent, partagent, et utilisent les connaissances » (p. 5). Pas de déterminisme technique ici : le sociologue rappelle à plusieurs reprises au cours de cet ouvrage que ce ne sont pas les progrès techniques qui modèlent nos comportements, mais ces derniers qui privilégient telles ou telles pratiques et un outil plutôt qu’un autre en fonction de nos besoins et de nos usages culturels. Six grands chapitres vont lui permettre de balayer tous les champs de cette nouvelle culture numérique. D’abord plutôt chronologique et historique dans les trois premières parties qui retracent l’apparition d’Internet, puis du Web et enfin du Web 2.0, le plan de l’ouvrage bascule ensuite dans trois chapitres plus thématiques : l’un sur la dimension politique et médiatique avec les nouvelles formes de démocratie participative ; un chapitre sur l’économie des plateformes ; enfin une dernière partie sur les algorithmes qui rejoint le contenu du précédent livre de l’auteur1.
Internet ou l’ambivalence de la culture numérique
Revenir sur les origines historiques d’Internet permet à Dominique Cardon de mettre l’accent sur la tension qui existe depuis sa création entre l’idéologie utopique des pionniers de l’informatique qui souhaitaient « rendre le monde meilleur » et la récupération marchande presque immédiate par quelques entreprises privées des logiciels et des outils créés. La culture numérique telle que la définit ici l’auteur est « la somme des conséquences qu’exerce sur nos sociétés la généralisation des techniques de l’informatique » (p. 18). Il rappelle donc que l’informatique, qui se trouve au cœur de la révolution numérique actuelle, a une longue histoire, qui commence sans doute avec la machine à calculer de Pascal, se poursuit avec Ada Lovelace, la première femme programmatrice, puis avec le langage inventé par Georges Boole (les opérateurs booléens que nous connaissons bien en documentation), et bien sûr la fameuse machine de Turing. La transformation d’un signal analogique, continu, en signal numérique constitué de séries de 0 et de 1, qui ne se dégradent pas après copie et sont interopérables et transférables à l’infini, constitue l’étape majeure du développement de l’informatique et des premiers ordinateurs.

@laurenceallard sur Twitter
Une distinction importante est ici soulignée, gommée depuis longtemps dans le langage courant, et dommageable pour la compréhension des mondes numériques : Internet n’est pas la même chose que le Web. Ce dernier est l’un des réseaux parmi d’autres issus d’Internet, plus récent et inventé par Tim Berners-Lee, en langage HTML. Le premier protocole d’Internet, TCP-IP (Transmission Control Protocol – Internet Protocol), a lui été inventé dans les années 60 par Vint Cerf et Robert Kahn. Lié à la fois à la contre-culture américaine libertaire des années 70, et à l’Armée qui le développe avec ses ingénieurs, Internet « est un outil collaboratif inventé de façon coopérative » (p. 37), issu d’éléments technologiques créés par des personnes différentes, et améliorés au fur et à mesure.
Arrêtons-nous un instant sur les trois formes possibles de réseaux conceptualisées par l’ingénieur Paul Baran dont Dominique Cardon nous présente trois schémas simples mais très pédagogiques (p. 31).
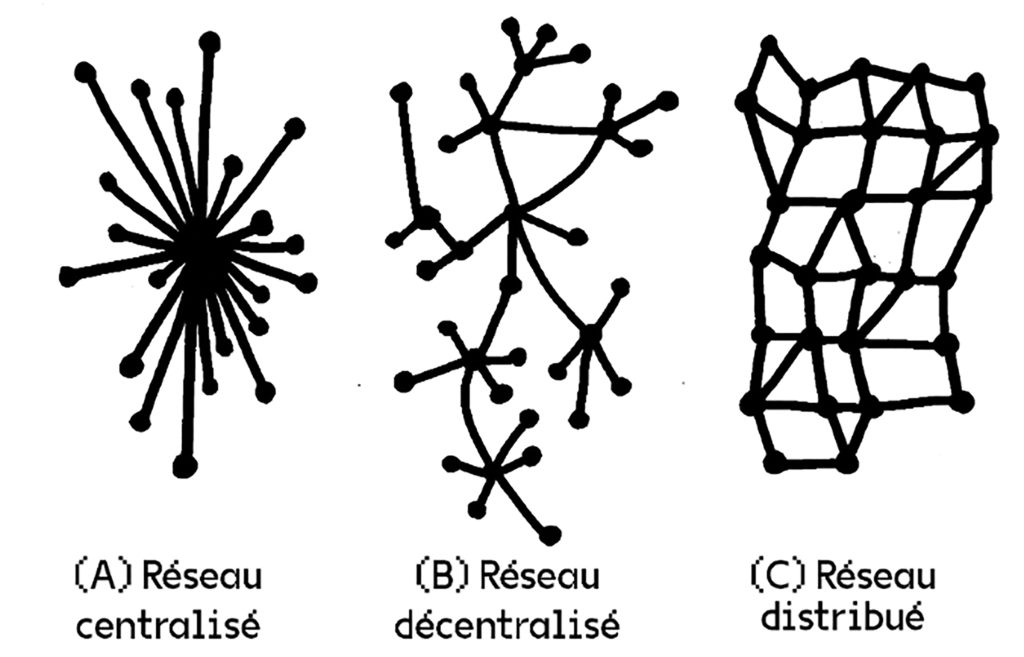
Le réseau centralisé fait tout passer par le centre : il est souvent national, monétisé, le centre y est « intelligent » et la périphérie « idiote », puisque c’est le noyau central qui concentre toutes les informations puis les redistribue. C’est le modèle de réseau du téléphone fixe ou du Minitel.
Le réseau distribué utilise une communication par paquets : le message y est découpé et peut prendre plusieurs chemins différents. Il est le plus souvent gratuit, sans frontière, et ne présente pas de contrôle centralisé. À l’inverse du premier réseau, « le centre est idiot et la périphérie intelligente ».
Enfin, le réseau décentralisé est celui qui est utilisé dans le cas d’Internet : c’est un intermédiaire entre les deux autres formes, puisque certains nœuds y ont plus d’importance que d’autres et ce sont plusieurs petits centres qui distribuent l’information.
Dès l’origine, c’est l’éthique du « hacker » qui prévaut dans l’élaboration d’Internet, « hacker » étant à entendre dans le sens de « bidouilleur », « bricoleur », et non pas de « pirate » comme on le dit souvent aujourd’hui. Cette culture du hacking développe des valeurs comme la curiosité – les férus d’informatique aiment explorer le fonctionnement interne des programmes – ou la liberté – l’information doit circuler sans contrainte ni censure, elle est le « carburant de la coopération ». On verra que cette dimension est extrêmement importante dans l’idée de logiciel libre. La culture des hackers se veut par ailleurs méfiante envers l’autorité et toute forme de centralisation. La notion de mérite et de reconnaissance par les pairs y est plus forte que tout diplôme ou statut social : c’est ce qui sous-tend encore le classement du PageRank de Google. Enfin, l’informatique est considérée comme un art et elle doit rendre le monde meilleur.
La forme même d’émergence et d’amélioration du protocole d’Internet à ses débuts illustre bien ces valeurs de liberté et de coopération. En effet, c’est grâce à des textes courts et contributifs, les RFC (Request for Comments) que les éléments informatiques sont modifiés entre chercheurs et ingénieurs encore aujourd’hui, via le IETF (Internet Society), un collectif qui s’occupe des couches basses du réseau.
Trois communautés ont convergé pour créer Internet : les militaires et ingénieurs employés par l’armée, les chercheurs universitaires avec notamment le réseau ARPANET qui reliait quatre universités américaines, et enfin les hackers hippies passionnés et libertaires. C’est l’alliance somme toute improbable de ces trois sphères qui a permis l’émergence du réseau connecté et de la souris d’ordinateur, créés par Doug Engelbart en 1968 puis du protocole TCP-IP, fixé définitivement en 1983. On retrouve bien cette ambivalence dans l’idéologie diffusée en 1985 lors du premier forum Internet baptisé The Well (The Whole Earth ‘Lectronic Link). Il regroupe les membres de la culture hippie des années 70. S’y développe l’idée que le monde virtuel serait un milieu idéal, égalitaire, plus solidaire que la vie réelle, où l’on peut réinventer entièrement les relations sociales. Dominique Cardon montre bien qu’il y a en réalité un fort décalage entre cette utopie et l’homogénéité socio-culturelle des participants du forum, majoritairement des hommes blancs californiens, cultivés. Ainsi, et cette idée est fondamentale pour la compréhension du monde numérique, le virtuel reste toujours « la prolongation numérique des rapports sociaux ordinaires », un reflet du réel malgré tout ce qu’on voudrait qu’il ne soit pas.
Gardons bien en tête ces idéologies diverses et parfois contradictoires qui ont bâti Internet : les pionniers voyaient ce dernier comme un outil d’émancipation individuelle, un mode d’empowerment accessible à tous, qui permet aux individus de faire changer les choses en se passant du pouvoir politique et en impulsant les changements par la base. L’échange et l’égalité sociale y sont valorisés grâce à l’anonymat, aux avatars, aux multiples identités virtuelles. Côté ingénieurs et chercheurs, c’est plutôt l’utopie d’un pouvoir « salvateur » du numérique sur la société qui reste prégnante dans le développement actuel de l’Intelligence Artificielle. Enfin, à l’idée première de liberté et de gratuité, viendra s’ajouter ensuite la liberté économique qui conduira, nous le verrons, aux GAFAM et à l’extrême marchandisation du numérique.
Le Web : bien commun ou produit marchand ?
L’invention du Web, « toile » en anglais, en 1996, marque la fin de la période des pionniers d’Internet. Le changement fondamental qui accompagne l’apparition du Web est celui du lien hypertexte, ce « réseau de liens qui créent des routes entre les pages des différents sites » (p. 78). C’est une nouvelle manière de classer les informations qui se fait jour et qui remet en cause l’ordre documentaire tel qu’il était défini jusqu’ici. Plus de classement alphabétique comme dans un dictionnaire. Avec les liens hypertextes, c’est l’auteur du site qui décide de relier son contenu à celui d’autres sites : « ce sont les documents eux-mêmes – donc ceux qui les écrivent – qui décident de leur classement » (p. 79). Cette manière d’ordonner les connaissances en laissant totale liberté aux concepteurs des sites montre l’héritage de l’esprit libertaire d’Internet sur le Web. Tim Berners-Lee pose le principe du lien hypertexte au CERN en 1989-90, en ayant l’idée de relier les pages créées les unes avec les autres grâce à des adresses URL.
On retrouve ici l’utopie de la bibliothèque universelle qui sous-tend le projet du Mundaneum de Paul Otlet et Henri La Fontaine à Bruxelles. Pour rappel, les documents y étaient organisés par rapport à leur contenu, à l’aide de fiches dépouillées regroupées par thème dans des tiroirs, classées en CDU, classification créée pour l’occasion. Des trous dans les fiches perforées permettaient à des tiges de récolter dans un même geste les fiches des livres traitant du même sujet. Dominique Cardon voit là l’ancêtre du lien hypertexte, une manière de relier par association d’idées des contenus différents. De même, la Mondothèque était une machine connectée, qui visait à relier les savoirs, une sorte d’anticipation du Web au début du XXe siècle.
Si Internet était au départ un outil créé pour un tout petit nombre d’utilisateurs, le succès fulgurant du Web va ouvrir cette innovation au plus grand nombre avec la norme http, le langage HTML puis les premiers navigateurs. On passe ainsi de 130 sites web en 1993 à 230 000 sites en 1995 ! Jamais une technologie au cours de l’histoire ne s’est propagée à l’ensemble de la population aussi vite : en 20 ans, 85% de la population française est devenue connectée, ce qui représente une démocratisation de l’outil bien plus rapide que l’arrivée de l’électricité ou de la télévision.
À noter également, toujours dans la veine de l’esprit des pionniers, qu’en 1993, le CERN renonce à ses droits sur le langage HTML et le verse au domaine public. Le lien hypertexte fait désormais partie du bien commun, ce qui n’est pas le cas du like de Facebook par exemple.
La première phase d’expansion du Web, entre 1995 et 2000, s’achève avec l’éclatement de la bulle spéculative des premières entreprises du numérique. Après 1995, l’accès au réseau devient payant via des fournisseurs d’accès. Des entreprises comme Amazon, Yahoo!, Ebay ou Netscape se développent. On est là dans une simple transposition du modèle économique traditionnel appliqué au numérique. Après 2001, et surtout à la suite du développement du Web 2.0 à partir de 2005, de nouvelles formes économiques se mettent en place avec la multiplication des plateformes numériques (cf. chapitre 5).
Il est étonnant de constater que les idées innovantes qui se développent sur le web sont toutes ascendantes : elles viennent de la base des internautes et sont souvent créées au départ pour répondre à un besoin personnel de leur concepteur. C’est le cas par exemple pour Wikipédia, Facebook ou Google. Sans étude de marché, sans business plan, ces inventions issues de « geeks » ont connu un succès mondial. Elles ont ensuite, pour certaines d’entre elles, été largement monétisées.
Pour revenir sur la notion de Bien commun qui est au centre du Web, les premiers communs du monde numérique ont été, on l’a dit, les liens hypertextes, qui ont ensuite permis le développement de l’open source et des logiciels libres. Ceux-ci garantissent quatre libertés : les libertés d’utilisation, d’étude, de modification et de distribution, grâce à l’accès au code source du logiciel et à la création de licences spécifiques dites libres, comme le copyleft. L’idée ici au-delà du principe libertaire, est qu’un programme conçu à plusieurs et librement modifié, c’est-à-dire amélioré par le plus grand nombre, sera plus fiable et performant qu’un logiciel construit par une seule personne. On rejoint un fonctionnement du travail basé sur la méritocratie et la reconnaissance entre pairs, sans hiérarchie, comme chez les concepteurs d’Internet. La communauté des amateurs éclairés et passionnés fait naître la notion de communs numériques, à l’œuvre dans Wikipédia ou Openstreetmap par exemple, puis par la suite dans toutes les bases de données en Open Data. En prolongement, Lawrence Lessig, un juriste américain, crée les licences Creatives Commons (CC), qui permettent de fixer précisément les conditions d’utilisation des documents (libre diffusion sans modification/citation de l’auteur/interdiction de diffuser à des fins commerciales2, etc.) C’est une révolution en matière de droit d’auteur et de propriété intellectuelle.
Un autre exemple intéressant de site participatif au succès incroyable est celui de Wikipédia. Dominique Cardon nous en rappelle les prémices. Nupédia, ancêtre de Wikipédia, est créé en 2000 par Jimmy Wales. Il demande à des universitaires des contributions pour alimenter le site, mais ceux-ci ne sont pas d’accord pour publier des articles gratuitement. Il a alors l’idée d’utiliser la technologie du wiki, qui « permet à quiconque d’écrire, d’effacer, et de corriger des pages du web à partir d’une utilisation ingénieuse du lien hypertexte » (p. 123) au départ seulement pour discuter entre internautes des articles écrits par les experts. Or, le site du grand public devient vite beaucoup plus vivant et fourni que les contributions universitaires et finit par se substituer à lui. On voit là que, sur le Web, ce n’est pas la compétence ou le diplôme qui détermine la qualité et la valeur des contenus, mais la validation des pairs. Wikipédia, « encyclopédie des ignorants », devient le site le plus consulté, qui arrive en premier résultat sur les moteurs de recherche, quel que soit le mot-clé, alors que son contenu est rédigé par des amateurs certes éclairés, mais non spécialistes. Dominique Cardon nous livre ici bien à propos la mention d’une enquête de la revue scientifique Nature de 2005 qui montre que les articles de Wikipédia sont globalement fiables3 par rapport à ceux de l’encyclopédie Britannica pour les entrées scientifiques, à savoir qu’il y a un nombre quasiment équivalent d’erreurs dans les deux.
Le succès de Wikipédia repose sur le principe de l’intelligence collective et sur les modes d’auto-régulation de la communauté, qui correspondent aux huit règles d’auto-gouvernance rédigée par la prix Nobel d’économie Elinor Ostrom. On peut donner en exemple la règle 3 : « Les individus affectés par la règle collective doivent pouvoir participer à la modification de cette règle », ou encore la règle 4 : « Les individus qui surveillent la ressource commune doivent être choisis localement et être responsables devant la communauté » (p. 128). Les pages « Discussions » de Wikipédia sont l’illustration de ce contrôle local, en interne. Les conflits sont réglés de façon transparente par le débat argumenté, sauf en cas de problème plus conséquent, où intervient un médiateur extérieur. Le savoir s’affine ainsi grâce aux conversations entre pairs, basées sur l’émulation intellectuelle.
Pour finir avec ce chapitre sur le Web, Dominique Cardon explicite la tension qui existe entre marché et bien commun sur le réseau. Il rappelle à cette occasion deux notions d’économie. L’information numérique est un bien non rival, c’est-à-dire qu’elle existe toujours après avoir été « consommée » par quelqu’un, contrairement à un bien rival, qui disparaît après consommation. Deuxième notion : l’externalité. Le Web produit des externalités positives importantes, ce qui veut dire qu’il a des répercussions importantes dans différents domaines économiques. Le web non marchand des contributeurs bénévoles produit de l’attractivité, du clic, des visiteurs, pour le web marchand. Google, par exemple, est un énorme bénéficiaire des contenus créés non par lui mais par les internautes. Si on le traduit en termes économiques, cela revient à dire : « En produisant des liens hypertextes, c’est-à-dire un bien informationnel non rival, accessible par tous, les internautes produisent une externalité positive que Google transforme en intelligence collective » (p. 136) et j’ajoute, qui lui permet de gagner beaucoup d’argent. Si les revenus récoltés par les plateformes numériques à partir des contributions des internautes leur sont en partie reversés, le modèle économique est dit génératif, comme c’est le cas dans les communautés numériques, l’open source, l’innovation ascendante. Lorsque l’argent n’est pas reversé mais capturé uniquement par les plateformes, le modèle est dit extractif et nourrit les GAFAM et tous les services numériques payants. Deux modèles s’affrontent donc en permanence sur le Web et témoignent de la tension originelle entre principes libertaires et économie de marché.
Les réseaux sociaux numériques : transformation de l’espace public et typologie des identités en ligne
Le fil rouge de ce chapitre sur les réseaux sociaux que nous propose Dominique Cardon est d’adopter une grille de lecture sociologique, en réalisant à chaque étape des typologies spécifiques : l’ensemble peut se révéler complexe mais il est au final très éclairant sur les comportements en ligne, et la finesse de l’analyse de l’auteur sera sans nul doute très utile aux enseignants de SNT, professeurs documentalistes et autres.
Commençons par les quatre formes de prise de parole publique que distingue Dominique Cardon. Il y place trois éléments : le locuteur, le sujet du discours et l’espace public. Concernant le locuteur, on est passé d’un groupe restreint de locuteurs professionnels (auteurs, scientifiques, journalistes, politiques, professeurs, etc.) à une foule de locuteurs amateurs sur le Web. De même, le type de sujets abordés opère un glissement entre une focalisation sur des personnalités publiques et des sujets généraux, et une palette de sujets qui parlent de notre vie quotidienne et de personnes connues de nous seuls. D’où la formule : « N’importe qui peut prendre la parole sur n’importe quoi ».
La forme traditionnelle de l’espace public était jusqu’à la fin du XIXe siècle celle d’une sphère publique restreinte, où les locuteurs professionnels parlent seulement des personnalités publiques. Les gatekeepers, c’est-à-dire les journalistes, éditeurs, auteurs et médias « classiques », se font les intermédiaires entre l’information et le public et filtrent les connaissances. Cette forme évolue au début du XXe siècle avec l’apparition des médias de masse : les sujets s’élargissent aux faits divers, à la vie quotidienne et touchent un plus grand nombre de personnes. L’espace public y est défini à la fois comme ce qui se passe sous les yeux de tous, la rue, la place publique par opposition au foyer, à la maison qui relève de la sphère privée, mais aussi comme l’espace de diffusion des informations qui concernent tout le monde. En leur donnant de la visibilité, les journalistes donnent aussi de l’importance à cette information. La visibilité coïncide avec l’importance de l’information.
Avec le numérique et la massification des locuteurs sur le Web, l’espace public se transforme et devient participatif. Il n’y a plus aucun filtre avant publication, et ce qui est visible n’est pas forcément important. D’ailleurs, 1 % des contenus attire 90 % de l’attention. « Le Web est un cimetière de contenus » (p. 98). Le filtre se fait après la publication, par l’absence de visibilité du contenu, notamment dans la hiérarchisation des résultats sur Google. Ce sont les internautes qui deviennent les gatekeepers du Web, puisque le PageRank calcule le nombre de liens qui renvoient d’un site à l’autre. Enfin, la quatrième forme d’espace public définie par l’auteur est le Web en clair-obscur, où la majorité des internautes anonymes parle de quidams connus par eux seuls sur les réseaux sociaux.
Pour dresser une typologie des réseaux sociaux numériques, Dominique Cardon commence par nous en donner une définition : « L’internaute dispose d’une page personnelle et il s’abonne à d’autres utilisateurs avec qui il peut interagir » (p. 153). Il entend ensuite combiner deux variables : le type d’identité numérique et le degré de visibilité du profil, plus ou moins public ou privé. Étudions avec lui les quatre types d’identité numérique qu’il a déterminés.
La première est l’identité civile, constituée des informations factuelles, état civil, profession, etc. Notre « être réel » s’y dévoile progressivement, car sur les réseaux sociaux qui correspondent à ce modèle, on se cache pour mieux se voir, on découvre les personnes au fur et à mesure des conversations, pour ensuite se rencontrer en vrai. La visibilité y est de type « paravent » comme sur Meetic ou Tinder, ou d’autres sites de rencontre. L’accès à l’information s’y trouve sous la forme de l’appariement ou du matching : on cible quelqu’un en fonction de critères précis, déterminés à l’avance, il n’y pas de place pour le hasard.
Deuxième forme d’identité numérique qui coïncide avec un autre groupe de réseaux sociaux : l’identité narrative. On y raconte notre vie quotidienne, nos humeurs, nos centres d’intérêt, on partage nos photos, mais la plupart du temps, uniquement avec nos amis, les personnes que l’on connaît déjà dans la vie réelle. L’auteur nomme ce type de visibilité le « clair-obscur », car on se montre en se cachant, puisque l’on ne s’adresse qu’à ses propres amis. C’est la famille de réseaux la plus développée, avec Facebook, Whatsapp, Snapchat, Messenger. Le bonding y est le plus présent, c’est-à-dire le fait de resserrer des liens déjà existants. L’information s’y concentre en clustering, c’est-à-dire en un ensemble d’interconnexions sur un petit nombre de personnes, puisque nos amis sont souvent également amis entre eux.
L’identité agissante constitue la troisième grande famille, avec des réseaux comme Twitter, Youtube, Instagram. La visibilité de type « phare » signifie qu’on y est très exposé, tout y est public, on se montre entièrement pour se mettre en avant et faire des ponts avec des personnes qui nous sont inconnues, mais avec lesquelles on peut se trouver des centres d’intérêt communs (bridging). Plus que des discussions sur soi, on y partage du contenu, des liens, autour d’un thème particulier. La dérive de ce type de réseau est illustrée par les influenceurs qui font de leur vie une marque ou un centre d’intérêt en soi.
Enfin, le quatrième et dernier type de réseau s’apparente à l’identité virtuelle : le moi y est caché, déguisé entièrement sous la forme d’un avatar, d’une projection imaginaire et théâtralisée de la personnalité. Dans ces mondes virtuels, on se voit mais caché, comme dans les jeux vidéo tels Second Life ou World of Warcraft, les fanfictions ou les contenus auto-produits. Dans ces deux derniers types de réseaux, l’accès à l’information présente un très faible clustering, car il s’agit de réseaux comportant un grand nombre de personnes où peu d’entre elles se connaissent.
Ces quatre familles de visibilité invitent chaque individu à moduler son identité numérique aux types d’interactions et aux publics différents qui y sont rencontrés. Chaque réseau propose des paramètres qui permettent de décider en toute conscience de ce que l’on veut montrer ou non, à condition d’en comprendre les rouages et d’y faire attention. Les réseaux sociaux ne modifient pas en profondeur le lien social, contrairement à ce que l’on entend souvent. On est amis en ligne avec ses proches et sa famille, comme dans la vie réelle. En revanche, ils ont un effet sur les liens faibles, les personnes que l’on a perdues de vue ou les simples connaissances : dans ce cas, les réseaux sociaux numériques densifient le lien social.
Ces formes d’identité, si elles ne modifient pas fondamentalement le lien social, créent de nouvelles normes, comme celle de devoir absolument exister en ligne. La vie privée n’a pas disparu, tout est une question de frontière et de contexte ; « Sur le web, l’exposition de soi est une technique relationnelle ». Ce n’est pas par pur narcissisme que l’on expose photos et récits de soi, mais davantage pour recevoir de l’amour et de la reconnaissance de la part des autres. Nos profils sont « des petits théâtres dans lesquels chacun conforte son estime de soi », à grand renfort de like et de smileys cœur. On montre de soi ce que l’on sait que les autres vont apprécier. Les études montrent que les sentiments de tristesse et de colère sont largement sous-représentés sur Facebook par exemple. On sélectionne les moments festifs, qui nous mettent à notre avantage plutôt que de mettre en avant les moments plus difficiles. De même, l’ensemble des informations, nombre d’amis, niveau de langue, voyages, contenus partagés etc. reflètent notre niveau socio-culturel. « La fabrication de la personnalité en ligne passe par une injonction paradoxale : bien que construite, elle doit paraître naturelle et authentique » (p. 182). Le geste du selfie en est le symbole : celui qui prend la photo est aussi celui qui se regarde, qui jauge et contrôle la construction de l’image produite et du récit de soi qui en sera fait en une mise à distance de sa vie pour mieux la raconter sur les réseaux. D’un point de vue sociologique, le selfie est très intéressant à étudier comme en témoigne l’enquête Selfiecity.net4 qui montre, entre autres, que les filles sourient beaucoup plus sur les photos que les garçons.
Le boom des pratiques artistiques et créatives sur le Web valorise une petite élite de producteurs qui focalisent l’attention, comme sur Youtube avec l’émergence d’un nouveau système de notoriété. Toutefois, les youtubeurs émergents réintègrent ensuite le circuit médiatique traditionnel en allant à la radio ou à la télévision. On retrouve d’ailleurs dans ce cercle restreint les différences socio-culturelles traditionnelles, à savoir que ce sont les individus les plus cultivés, diplômés, bien intégrés socialement et disposant d’un bon réseau de contacts, qui perceront plus facilement que les autres.
Enfin, Dominique Cardon conclut ce chapitre en essayant de tordre le cou à une idée reçue : les réseaux sociaux seraient une zone de non-droit et un outil d’aliénation, en raison de la dérégulation des propos et de la violence des insultes. Il rappelle que des régulations juridiques existent déjà et régissent, certes de façon imparfaite, chaque type de réseau. Dans la sphère publique restreinte des médias traditionnels, c’est le droit de la presse qui prime. Dans l’espace public, c’est le droit au respect de la vie privée : droit à l’image et droit des individus. Sur le web participatif, ce sont les limites de la liberté d’expression qui s’appliquent. Enfin, dans le tout-venant des conversations numériques, on peut tabler sur une régulation par l’éducation.
Avec la notion de droit à l’oubli et plus globalement les cas nombreux où il est demandé aux hébergeurs de retirer des contenus, on assiste à un phénomène d’extra-judiciarisation, c’est-à-dire que l’application du droit se fait en dehors de la justice. En effet, on peut obtenir que Google déréférence certains contenus qui nuisent à une personne, mais ces derniers ne sont pas supprimés, ils disparaissent simplement des pages de résultats. Le principe de séparation entre la responsabilité juridique de celui qui publie et celle de l’hébergeur est devenu « la colonne vertébrale du droit du numérique » (p. 207). Toutefois, l’hébergeur devient coupable s’il ne retire pas un contenu « signalé ». Des algorithmes et des métiers spécifiques sont désormais créés pour contrôler et retirer des contenus, mais, là encore, ce sont les plateformes qui jugent de la pertinence de ces retraits et non la justice. Pour conclure, on peut mettre l’accent auprès des élèves sur les différents paramétrages de visibilité des informations et leur faire prendre conscience de la nécessité de réfléchir avant de publier quelque chose en ligne.
Un système médiatique à deux vitesses
L’espace public est reconfiguré par le Web qui est « descendu » dans la société et lui permet de discuter avec elle-même. Pourtant, nous n’assistons pas à la fin des médias, des partis politiques ou des institutions : il n’y a pas à l’heure actuelle de démocratie horizontale totale, mais trois espaces refondus sur lesquels le numérique a des impacts différents.
L’effet du Web est somme toute relativement limité sur les instances de la démocratie représentative. Il a un impact relatif et incertain sur les modes de démocratie participative. En revanche, sur ce que l’auteur nomme la « Démocratie Internet », l’effet est nouveau et perturbant. Dans la « société des connectés », les formes politiques présentent trois caractéristiques : d’une part, la singularité des individus et leur pluralité d’opinions personnelles sont mises en avant et prévalent sur le Nous collectif. Deuxièmement, il n’y a pas de leader, ce qui, dans le mouvement Anonymous par exemple, conduit même à l’invisibilité totale de ses membres comme garantie d’égalité. Enfin, il n’y a pas non plus de programme : les discussions portent souvent sur les procédures, sur la forme, davantage que sur le fond. Cette « démocratie Internet » génère une masse de conversations politiques qui s’insinuent dans toutes les strates du Web, à l’image des hashtags. « Le hashtag est le drapeau que l’on plante dans le brouillard du Web ». Ces phénomènes viraux inventés par le « bas » sans que l’inventeur n’en ait anticipé l’impact, représentent des agrégateurs qui polarisent l’attention sans l’avoir réellement demandée, et qui d’une certaine manière « centralisent sans commander » (p. 244). La mobilisation naît alors autour d’un contenu ou d’un slogan et constitue une « communauté imaginée » qui surgit en dehors du filtre des gatekeepers traditionnels.
Qu’en est-il des médias dans ce contexte ? Si en France le milieu médiatique perd environ 600 journalistes par an, il n’en reste pas moins une demande forte d’informations rédigées par des professionnels, comme en témoigne la fréquentation du Monde.fr qui tourne autour de 1.5 à 2 millions de lecteurs par jour. La fin du journalisme n’est pas pour aujourd’hui : Dominique Cardon prend pour exemple l’échec relatif des initiatives hybrides de citoyens journalistes comme Agoravox ou Rue89. Le « tous journalistes » n’existe pas de façon effective. L’auteur voit d’ailleurs dans les commentaires incessants des articles sur le Web des effets à la fois positifs et négatifs. D’un côté, cette vigilance citoyenne et critique conduit à une amélioration de l’exactitude factuelle des articles et à des débats argumentés plus riches. D’un autre côté, les campagnes de dénigrement, les attaques de troll ou encore les polémiques puériles se multiplient.
Mais c’est surtout en matière d’accès à l’information que le changement est le plus marquant. Les médias ont en effet « perdu la maîtrise de la manière dont l’information est reçue, organisée, et hiérarchisée par les internautes » (p. 250). Chez les 18-24 ans, ce sont bien les réseaux sociaux et les médias numériques qui constituent le principal accès à l’information. Or, dans ces derniers, la publicité en ligne génère beaucoup moins de revenus que dans les éditions papiers. Et c’est cette course à l’argent qui fait baisser la qualité de l’information produite. Les médias vont alors privilégier les informations aguichantes, drôles ou douteuses pour générer des clics (comme sur les sites Buzzfeed ou Vice).
Arrêtons-nous un instant avec Dominique Cardon sur quelques chiffres impressionnants. La moitié des événements couverts sont repris dans les médias en moins de 25 minutes. Une étude de 2013 montre que 64 % de l’information publiée dans les médias en ligne français est un simple copier-coller. On assiste donc à une multiplication des articles sans aucune plus-value, et à une folle accélération du rythme d’écriture qui se cantonne parfois à de simples transferts de dépêches. Les médias tendent même à mesurer en direct l’audience des articles et informations diffusées avec des outils comme Chartbeat qui donnent des statistiques en temps réel du nombre de consultations.
À l’inverse, la réintroduction d’offres payantes sur abonnement chez les médias numériques de qualité, tels Arrêts sur Image, Les Jours ou Médiapart, redonne de la vitalité économique à ce type de journalisme. D’autre part, l’essor du data journalisme permet de mener des enquêtes de grande ampleur en analysant les gisements de données publiques en opendata. De même, les leaks ou fuites des données cachées ont généré des scandales importants relayés massivement par les médias, voire dévoilés par eux comme pour les Paradise Papers issus d’un consortium international de journalistes.
On constate donc une nette fracture entre deux formes de journalisme assez irréconciliables : par le « haut », un renforcement du journalisme de qualité, payant, fortement éditorialisé et développant des formats variés et originaux ; par le « bas », des contenus médiatiques qui se transforment en « info-à-cliquer » parmi lesquelles sont véhiculées beaucoup d’informations peu fiables.
Dominique Cardon analyse ensuite le phénomène des fake news de façon rigoureuse, l’approche sociologique se révélant ici particulièrement intéressante. Il revient sur le fameux épisode où Orson Welles fit croire, en 1938 à la radio, à une invasion martienne. Or, c’est la panique que ce canular a suscitée qui est un mythe, ou dirait-on aujourd’hui, une fake news. Cette supposée panique a été à l’époque montée en épingle par les opposants à ce nouveau média qu’est la radio pour la discréditer et en montrer les effets hypnotiques. Cet épisode témoigne en profondeur de deux approches sociologiques différentes sur les effets des médias. Hadley Cantril théorise que la radio et plus globalement les médias, ont un « effet fort » sur les esprits, en annihilant la raison et en manipulant les comportements. Son contemporain, Paul Lazarfeld, propose quant à lui un autre modèle : celui « d’effets limités » ou faibles des médias, passant par deux niveaux de communication. Le contenu médiatique est en effet reçu par le destinataire mais il est également socialisé : il fait l’objet de conversations informelles, de critiques, de détournements qui ont tout autant d’influence sur le public.
On assiste avec les actuelles fake news au retour de cette première théorie de l’effet fort qui manipulerait les consciences. Dominique Cardon atténue nettement leur impact en montrant qu’elle constitue une hypothèse non prouvée qui relèverait d’ailleurs d’une forme de déterminisme technique. Ainsi, pour appuyer ce point de vue, il remet en perspective la proportion des fake news lors de l’élection de Trump : les 20 fake news les plus partagées sur Facebook représentent 0.006 % des vues des utilisateurs du réseau. Par ailleurs, il semble très difficile de mesurer l’impact réel de la lecture d’une information sur un comportement : ce n’est pas parce qu’on lit une fake news qu’on y adhère automatiquement. Enfin, on consulte les fausses informations qui confortent une opinion préexistante : pour une élection, en l’occurrence, cela ne fait que confirmer notre point de vue antérieur sans le modifier.
L’auteur propose comme garde-fous que les médias traditionnels ne relaient pas les fake news : ne leur accorder aucune visibilité atténuerait considérablement leur impact. Les sites de fact-checking, même s’ils touchent les personnes déjà convaincues, permettent néanmoins de réguler les médias « centraux ». Enfin, ce sont finalement dans les conversations informelles que circulent de la façon la plus diffuse les bullshit news mais cela est valable sur le Web comme dans la vie quotidienne. Nous sommes beaucoup moins exigeants dans nos conversations courantes et c’est là qu’est le vrai danger de propager des informations douteuses et non vérifiées.
Publicités numériques et digital labor
Alors qu’en 2006, seul Microsoft figure dans le top 10 des entreprises les plus cotées en Bourse, en 2016 les cinq entreprises dites des GAFAM y sont en très bonne place. Les rachats successifs, Youtube absorbé par Google, Instagram et Whatsapp par Facebook, leur procurent des bénéfices incommensurables, complètement disproportionnés par rapport au faible taux d’emploi qu’ils génèrent. L’économie numérique suit trois lois : la première est celle des rendements croissants. Plus il y a de clients, plus l’entreprise est productive. La loi des effets de réseau y joue également à plein : plus il y a d’utilisateurs, plus le service prend de la valeur et de l’utilité. Enfin, « winners take it all », c’est-à-dire que le leader gagne l’ensemble de la mise, plaçant en position quasi monopolistique les entreprises du numérique et favorisant ainsi la concentration.
Dans ce modèle économique de la plateforme numérique, il y a deux types d’effets de réseau. L’un procure des effets directs : l’utilité rejaillit sur tous les utilisateurs qui se connectent ; l’autre a des effets indirects lorsqu’il y a des acheteurs et des vendeurs multiples. Dans le cas de Google, le marché est dit « biface » car d’un côté les usagers ont accès à un service gratuit alors que de l’autre, les annonceurs paient pour avoir accès aux données personnelles et gagner de la visibilité.
La problématique de la publicité est intimement liée au traçage des données. Si Google et Facebook récupèrent à eux seuls 61 % des revenus de la publicité numérique et même 90 % de la publicité sur les smartphones, c’est qu’ils ont mis en place, outre les affichages publicitaires en bannière, un système de récolte des données très performant. Ainsi, le cookie, créé en 1994, « super espion » ne garde pas seulement en mémoire le passage sur un seul site5. S’il est « tiers », il envoie l’info de navigation à tous les sites web liés à la même régie publicitaire. L’automatisation de la publicité, gérée par des robots qui analysent nos traces pour proposer des publicités ultra ciblées, se fait donc désormais en temps réel.
Par ailleurs, les liens sponsorisés, qui apparaissent en tête des résultats sur Google, se présentent sous la forme de lien HTML qui ne les différencient en rien des autres résultats et donc de l’information. L’annonceur ne paie Google que si quelqu’un clique sur le lien : c’est le coût par clic. Pour chaque mot-clé ont lieu des enchères automatiques qui permettent aux annonceurs de remonter dans la liste des résultats.
Une autre transformation est l’ouverture des données des administrations et des collectivités au grand public. Le portail Data.gouv.fr a été créé en 2011. Les open data nécessitent de rendre les données interopérables, manipulables, au format identique, ce qui représente un travail important pour les administrations. Mais la volonté politique est forte pour impulser un « service public de la donnée ». Ainsi, plusieurs API (Application Protocol Interface) ont été créées pour donner accès sur des interfaces uniques à ces bases de données : Openfisca, Adresse Nationale, Entreprise, etc. Ceci étant, l’interprétation de ces données « brutes » est très compliquée pour le grand public. D’ailleurs, Dominique Cardon rappelle que l’idée d’une donnée « brute » est une fiction : celle-ci est toujours liée à un contexte de production particulier et nécessite curation et agrégation avec d’autres données.
Enfin, pour clore cette partie sur l’économie des plateformes, on ne peut occulter la notion de digital labor. Derrière le slogan bien connu, « si c’est gratuit, c’est toi le produit », se cache un « capitalisme de la surveillance », alimenté par la récolte des données mais également par une nouvelle main d’œuvre sous-payée qui réalise des micro-tâches6. C’est le cas chez Amazon Mechanical Turk, qui demande à des personnes souvent exploitées de faire des HITS (Human Intelligent Tasks), des actions qui ne peuvent pas être réalisées par des machines mais qui vont permettre d’alimenter les calculs de l’Intelligence Artificielle : étiqueter des photos, cliquer sur des likes, écrire des avis, créer des playlists, etc. Le besoin est donc urgent de proposer des régulations pour protéger ces travailleurs du clic invisibles.
Données personnelles et algorithmes : transparence et surveillance
Le Big Data peut-être vu comme une métaphore similaire à celle de la Bibliothèque de Babel chez Borgès. Cette bibliothèque qui contiendrait tous les livres possibles à partir de toutes les combinaisons existantes de lettres aurait la forme d’un contenu incommensurable et incohérent. De même, le Big Data représente une masse incroyable de données, mais comment en extraire du savoir ? Les outils de calcul des algorithmes informatiques lui sont intrinsèquement liés pour en tirer de la connaissance. Si les algorithmes sont vus comme une puissance occulte, c’est qu’ils sont devenus les nouveaux gatekeepers : les calculs informatiques filtrent et hiérarchisent l’information numérique. Nous naviguons en réalité sur un « nano espace informationnel » puisque 95 % de nos navigations concernent 0.03 % des contenus du web.
Dominique Cardon revient ici sur les quatre grandes familles d’algorithmes numériques7 : à côté du web, mesurant la popularité et les clics ; au-dessus du web, l’autorité et les liens ; dans le web, la réputation et les likes ; au-dessous du web, la prédiction et les traces.
Approfondissons l’algorithme de Google, le PageRank, basé sur l’autorité des sites, à savoir le nombre de liens qui renvoient vers eux. Au départ, les tout premiers moteurs de recherche classaient leurs résultats en fonction du nombre d’occurrences du mot-clé dans la page. Avec le PageRank, on passe d’une analyse du texte à une analyse du réseau : qui cite qui ? Sur la page de résultats, « les mondes ne se mélangent pas » (p. 367) : si tout est sous forme de liens HTML, les Google Ads, sponsorisés et donc payants, sont séparés des sites issus du mérite et du « référencement naturel ». Sur Google, « la visibilité s’achète ou se mérite ».
En ce qui concerne les algorithmes de réputation des réseaux sociaux, plusieurs caractéristiques méritent d’être soulignées. Tout d’abord, les informations y sont hiérarchisées en fonction d’un écosystème informationnel différent pour chacun, puisqu’il est déterminé par nos centres d’intérêt et nos amis. D’autre part, les informations qui y sont partagées participent à l’identité numérique et à ce que l’on veut montrer de soi. Enfin, la mesure de la réputation sur les réseaux sociaux est apparente et relève souvent d’une stratégie de communication. Dominique Cardon, comme dans son ouvrage précédent, relativise l’effet des bulles de filtre car nous ne sommes pas exposés seulement aux réseaux sociaux : les canaux de communication sont multiples et diminuent largement le poids de l’exposition sélective à un même type d’informations.
Les algorithmes ayant la plus grande puissance de calcul sont actuellement ceux du deep learning, reproduisant un réseau de neurones, ce qui a valu la réintroduction dans le langage courant du terme Intelligence artificielle. L’auteur analyse à juste titre l’influence de cette expression sur nos représentations imaginaires qui prennent la forme d’androïdes, du HAL de 2001, l’odyssée de l’espace, ou encore de la Samantha du film Her, qui n’ont tous pas grand-chose à voir avec le deep learning actuel. Dominique Cardon revient donc sur l’histoire du développement de cette technologie qui a connu plusieurs vagues et a également été au point mort plusieurs fois. Il explique les deux modèles régissant les expérimentations en matière d’IA : celui d’une machine que l’on chercherait à faire raisonner et le modèle actuel basé sur un volume très important de données en entrée dans la machine, avec un objectif final, qui lui permet de faire des corrélations toute seule.
Dans ce contexte, la régulation des algorithmes est absolument nécessaire : nous devons collectivement décider quels sont les domaines que nous souhaitons rendre calculables de cette manière et quels sont les enjeux de société qui doivent rester hors de ces modes de calcul. Transparence et neutralité du Web en sont les deux maîtres mots : le RGPD européen demande « l’explicabilité des décisions algorithmiques ». Il faut à ce stade garder en tête que l’algorithme est « idiot », il suit des procédures et traite des données, mais sans en comprendre le sens, ce qui peut aboutir à des erreurs et à des failles dans les calculs et les réponses.
D’autre part, les plateformes numériques optimisent leurs algorithmes pour maximiser le temps passé sur le Web : en récoltant nombre de données sur l’utilisateur, les recommandations personnalisées sur Youtube par exemple ou la hiérarchisation des informations du fil d’actualité sur Facebook visent surtout à garder captif et addict l’utilisateur en collant au plus près de ses attentes8. Il semble donc nécessaire de pouvoir reprendre la main de façon individuelle et, pourquoi pas, de configurer soi-même les objectifs des algorithmes sur les plateformes.
Dominique Cardon nous propose pour éclairer cette question un tableau de synthèse très intéressant (p. 404). Je vous le reproduis ici pour une meilleure compréhension du propos en y ajoutant les exemples complémentaires que l’auteur développe dans son raisonnement.
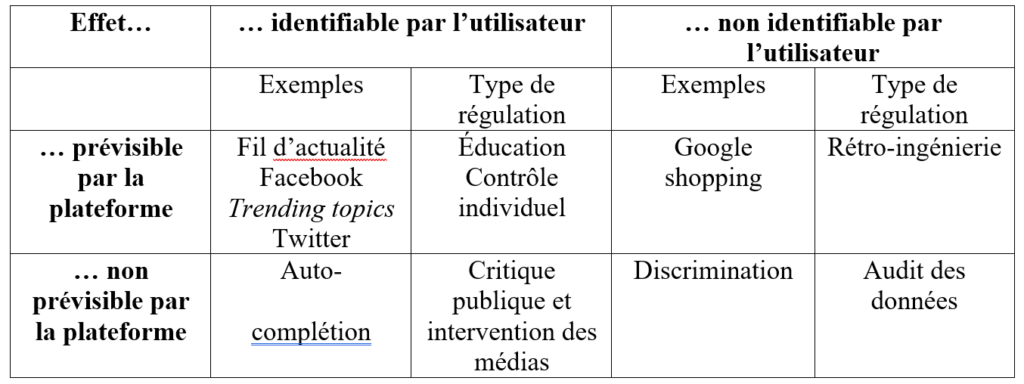
La première ligne du tableau correspond aux algorithmes auxquels la plateforme a fixé des objectifs, tout l’enjeu étant ici de pouvoir livrer de la façon la plus transparente possible ces objectifs aux utilisateurs pour qu’ils puissent éventuellement les contester ou les modifier. Ainsi, les trending topics sur Twitter sont régis par un algorithme qui met en avant les hashtags à forte viralité, ce qui conduit à une sur-représentation des événements très populaires et a contrario à une moins bonne visibilité des informations se déroulant sur le long terme.
La deuxième colonne du tableau présente les algorithmes dont les effets sont cachés à l’utilisateur. L’auteur cite ici les démêlés judiciaires qu’a connus Google pour avoir placé en priorité dans Google Shopping des restaurants affiliés à ses services, plutôt qu’une liste de restaurants correspondant aux critères habituels du PageRank. Dans ce cas précis, c’est la rétro-ingénierie, c’est-à-dire « l’ingénierie inversée », partir de l’analyse de l’outil technique pour remonter vers les résultats, qui a permis de se rendre compte de cette forme de manipulation de la part de Google.
La deuxième ligne de ce tableau pointe quant à elle les effets indésirables des algorithmes qui n’ont pas été anticipés par les plateformes. L’auto-complétion sur Google par exemple est basée sur le nombre d’occurrences statistiques dans l’association des différents mots clés, ce qui peut produire des expressions apparaissant automatiquement et relevant du racisme ou de l’antisémitisme (comme lorsque l’on voit un nom de personnalité affublé du mot « juif » systématiquement). L’effet produit par l’algorithme doit donc être régulé par la vigilance publique et médiatique, voire par une régulation législative si besoin.
Enfin, la dernière partie du tableau met l’accent sur les conséquences qui sont à la fois involontaires de la part des concepteurs et invisibles pour le public. C’est le cas de tous les types de discriminations liées à l’utilisation massive de données qui reproduisent elles-mêmes, hélas, les discriminations sociales et culturelles en cours dans la société. Les enjeux de régulation sont ici énormes et n’en sont encore qu’à leurs balbutiements politiques et citoyens. C’est pourquoi Dominique Cardon propose un audit des données en tant que telles grâce, notamment, à la rétro-ingénierie et à l’action des ONG.
Pour terminer cette partie sur les données et les algorithmes, l’auteur évoque rapidement la problématique de la surveillance, qu’il identifie sous trois formes : celle du marché, des autres individus et de l’État. La surveillance du marché, comme on l’a vu, cherche à tracer au maximum les personnes pour leur proposer des services qui correspondent de façon presque « magique » à leurs centres d’intérêt et à leurs besoins. Mais au-delà de cette logique, « c’est un projet de guider les comportements grâce aux données des utilisateurs » qui se dessine. La surveillance interindividuelle se fait jour quant à elle sur les réseaux sociaux et dans les systèmes de notations et d’avis généralisés. Enfin, la surveillance d’État est apparue au grand jour lors des révélations d’Edward Snowden puisqu’il a été avéré que la NSA, entre autres, écoutait massivement toutes les communications du grand public. De même, c’est cette logique d’écoute et de stockage de données qui sous-tend la loi relative au renseignement de 2015. L’auteur y voit l’entrée dans « la société de contrôle » décrite par Gilles Deleuze, puisqu’au-delà de la surveillance étatique, les trois formes de surveillance qui se mettent en place avec le numérique n’ont soulevé que peu de protestations dans l’opinion publique. Au nom du « je n’ai rien à cacher », ou du « je sais qu’on récolte mes données mais l’outil est tellement pratique », chacun accepte de faire des compromis et de rogner la notion de vie privée. Dominique Cardon propose ici, de façon tout à fait pertinente, de « cesser de penser individuellement la vie privée, de cesser de la considérer comme un arbitrage que chacun serait amener à faire […] mais plutôt d’y réfléchir comme à un droit collectif par lequel, même si nous n’avons rien à cacher, il est aussi dans l’intérêt de tous de vivre dans une société où certains – journalistes, militants, ONG – puissent avoir des choses à cacher ».
En conclusion, Dominique Cardon montre le glissement dans les esprits et les représentations d’une utopie euphorique des débuts d’Internet à une société numérique de surveillance, dominée par des algorithmes froids, le Web étant vu comme un objet d’aliénation et d’addiction. Profondément technophile et optimiste, le sociologue, à chaque étape du raisonnement, remet l’humain au centre des décisions en nous rappelant en permanence que c’est à nous de dicter les usages du numérique et d’en proposer des régulations. « Nos usages du Web restent très en-deçà des potentialités qu’il nous offre. Le Web se ferme par le haut, mais toute son histoire montre qu’il s’imagine par le bas » (p. 421). Il n’en reste pas moins critique vis-à-vis des GAFAM, appelant à plusieurs reprises à une législation rigoureuse de cadrage. Plusieurs idées reçues, souvent présentées de façon réductrice dans les médias, sont ici décortiquées avec pertinence, comme l’impact des bulles de filtre ou des fake news sur l’opinion publique. Un des impacts majeurs du numérique n’est toutefois pas du tout abordé dans cet ouvrage : il s’agit de toutes les conséquences environnementales qu’il génère.
Si l’on en revient à la dimension pédagogique, ce livre nous confortera dans l’idée que l’appropriation de la culture numérique passe par les deux injonctions parallèles et nécessaires que sont « coder et décoder » : « comprendre en faisant », en programmant mais aussi « faire en comprenant », en analysant et en développant la littératie numérique.






