Introduction
La bibliothèque, définie par l’UNESCO comme « un centre d’information de proximité qui met à disposition de ses usagers toutes sortes de savoirs et d’informations » (IFLA-UNESCO, 2022)1 est un espace central dans l’accès à la connaissance dans nos sociétés contemporaines. Elle remplit une mission de service public en favorisant l’appropriation par tous du savoir. Toutefois, cette institution est confrontée à des antagonistes qui la mettent sous tension. Ainsi, le nombre d’ouvrages ne cesse de croître ; le périmètre des bibliothèques s’étend avec l’inclusion de nouveaux documents comme le dépôt légal du numérique2, alors que le nombre de personnels de ces institutions reste, au mieux, constant, voire, diminue ce qui a un impact sur leur capacité à offrir des services de qualité.
Pour gagner en productivité, les bibliothèques nationales investissent de plus en plus dans des solutions technologiques qui sont aujourd’hui regroupées sous le terme d’« intelligence artificielle ». Cette dernière est considérée comme une solution pour améliorer la gestion des données, la recherche et la formation.
Les promesses d’un accès simple à la connaissance via des outils comme ChatGPT (InterCDI, janvier-février 2024, n° 307) s’emparent du monde des bibliothèques où l’algorithme semble devenir une solution pour les aider à mener à bien leurs missions. Qu’en est-il réellement ? Est-ce une tendance aussi récente que cela ? Quels sont les usages qui sont explorés par les grandes bibliothèques en Europe ? Quels enjeux et défis doivent-elles surmonter ?
Pour répondre à ces questions, il est important de comprendre les enjeux et les défis auxquels sont confrontées les bibliothèques dans le contexte de l’évolution des technologies et du changement sociétal. Dans un premier temps, nous remettrons en perspective la nouveauté de l’IA, en lien avec les besoins des bibliothèques, avant de nous centrer plus précisément sur des initiatives récentes avec un focus particulier sur le cas de Gallica. Cela nous permettra d’élargir aux transformations en cours au sein des bibliothèques.
Des systèmes experts à l’IA
L’actualité technologique remet au premier plan des thèmes déjà présents il y a plus de trente ans. À l’époque, si le terme d’intelligence artificielle est présent, c’est plus le concept de système expert que les articles scientifiques traitent. Ces derniers visent à reproduire des mécanismes cognitifs d’experts d’un domaine particulier. Le système se compose d’une base de données, d’une base de règles et d’un moteur d’inférence. Dans les années 1980-90, nous observons déjà un intérêt dans les articles scientifiques pour la classification automatique, l’indexation, mais aussi le traitement des images. Les systèmes experts n’ayant pas donné satisfaction, le terme d’IA a pris le relais ces dernières années avec l’arrivée de l’apprentissage profond (deep learning). La figure 13 illustre le glissement qui s’est progressivement opéré.
Nous avons réalisé une recherche sur le nombre d’articles présents sur la base de données Web of Science. Nous avons utilisé les requêtes « expert systems AND libraries » et « artificial intelligence AND libraries » avec une recherche dans le titre des articles indexés.
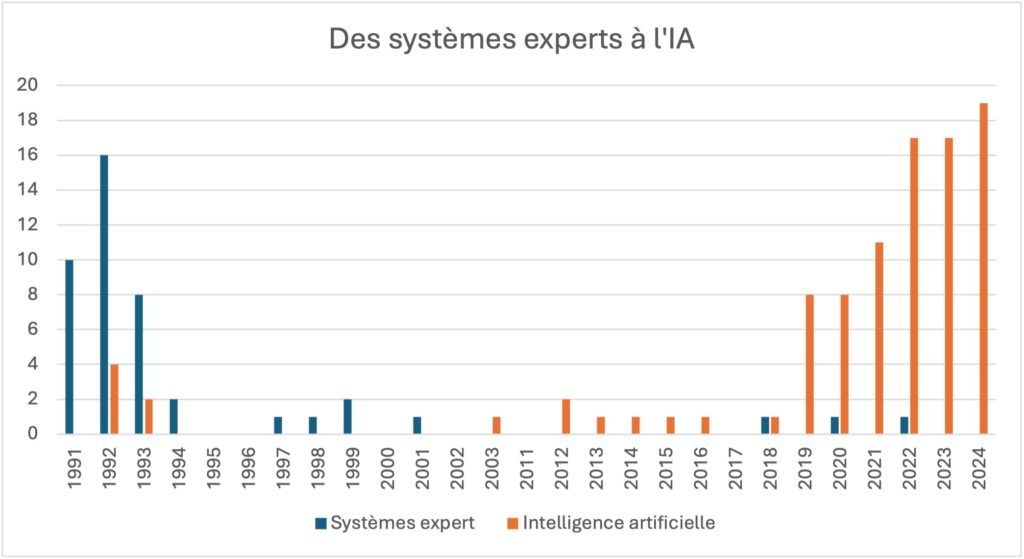
Les résultats mettent en évidence une décroissance nette des systèmes experts à partir du début des années 2000 et un intérêt grandissant pour l’IA à partir de 2019. Les thématiques associées – notamment l’amélioration de la recherche, l’indexation et le catalogage automatiques et, plus généralement, la transformation de la bibliothèque – restent toutefois les mêmes.
Sous l’appellation IA règne un flou artistique comme nous le verrons dans notre tour d’horizon des projets au sein des bibliothèques nationales en Europe. Dans les projets étudiés, nous retrouvons régulièrement l’usage de la reconnaissance optique de caractères (ROC ou Optical Caracter Recognition – OCR- en anglais), la reconnaissance de textes manuscrits (Handwritten Text Recognition ou HTR), la fouille de données ou d’images, mais aussi la génération de métadonnées ou l’aide au catalogage/indexation.
Tour d’horizon des projets d’IA
Dans cet article, nous nous appuyons sur le projet LibrarIn4 en cours (2022-2025), pour appréhender la ou les manière(s) dont les bibliothèques nationales déploient actuellement des solutions dites d’intelligence artificielle pour répondre à leurs besoins. LibrarIn se concentre sur la co-création de valeur entre usagers et bibliothèques, par l’intermédiaire notamment des services proposés. Trois dimensions de la valeur sont analysées dans ce cadre : sa nature et ses caractéristiques, ses modes d’organisation et d’implémentation et ses impacts.
Au sein du consortium de recherche, une tâche spécifique s’intéresse à la transformation numérique des bibliothèques. Pour répondre à nos questions de recherche, nous avons identifié les bibliothèques et les expérimentations suivantes (organisées par date de lancement) :
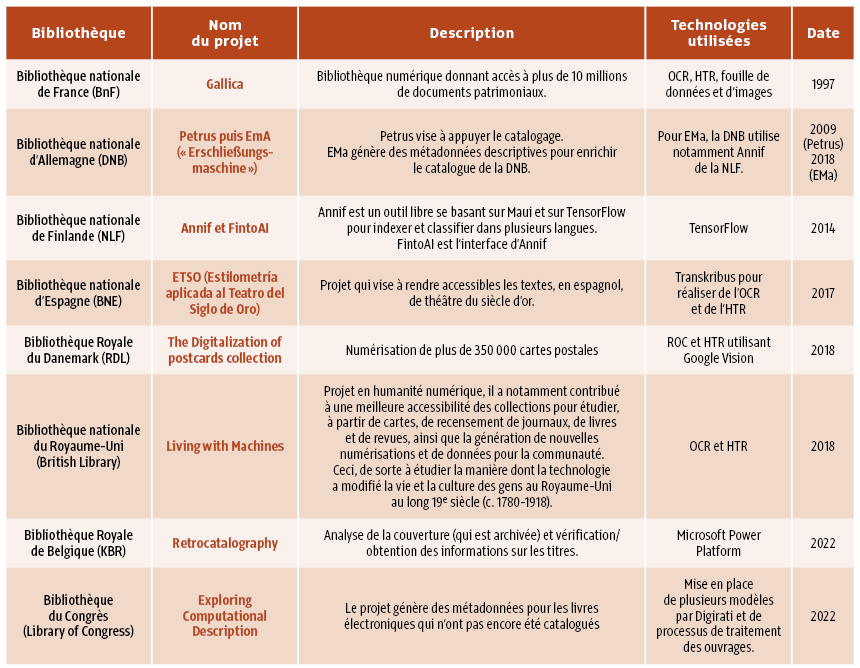
Pour chaque bibliothèque, une étude de cas est en cours avec des entretiens qualitatifs et une analyse documentaire. Ainsi, 70 entretiens ont été réalisés en 2024. Nous avons pu échanger aussi bien avec les chefs de projets qu’avec des acteurs plus politiques, mais aussi des représentants d’usagers. Nous nous sommes intéressés à l’impact de la transformation numérique, en particulier à la vague dite d’intelligence artificielle, le tout dans une perspective de co-création entre l’établissement public et ses usagers. Notre objectif étant de mettre en lumière les processus à l’œuvre et ses effets sur les services rendus.
Il est intéressant de noter que la BnF ou la bibliothèque nationale de Finlande ont lancé depuis de nombreuses années des expérimentations. Elles sont alors en mesure de diffuser le résultat de leurs travaux de recherche et développement (R&D) qui répondent à des besoins spécifiques. C’est dans cette logique que la BnF pilote le groupe de travail sur l’IA en bibliothèque au sein de la Conference of European National Librarians (CENL)5. Consciente des enjeux, la BnF a d’ailleurs déployé une feuille de route de l’IA qui couvre la période 2021 à 20266. Au sein de celle-ci, nous retrouvons les mêmes besoins (aide au catalogage et signalement ; gestion des collections ; exploration, analyse des collections et amélioration de l’accès ; médiation, valorisation et éditorialisation des collections et aide à la décision et au pilotage) que ceux auxquels les autres bibliothèques souhaitent répondre :
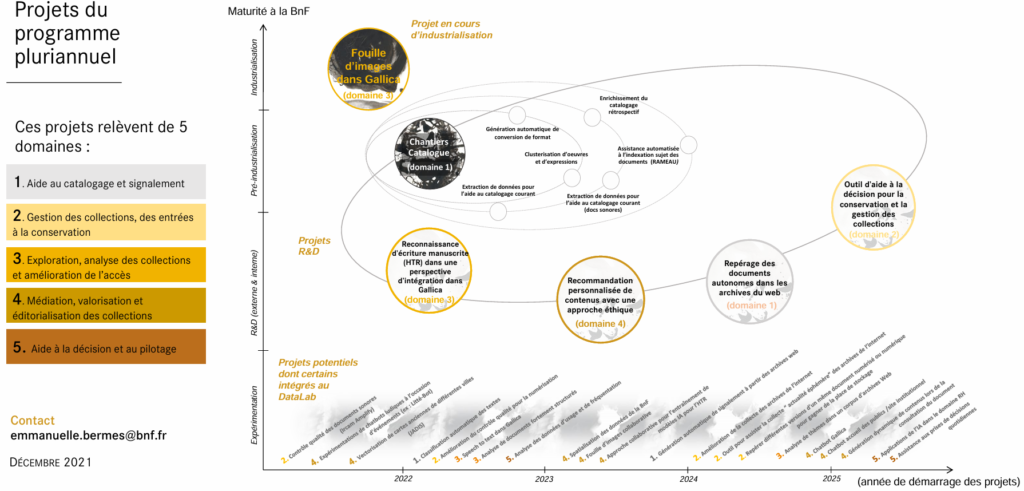
Ces cinq grands domaines se retrouvent dans le tableau 1. Les projets présentés soulignent les besoins des bibliothèques pour mener à bien des missions relatives à :
• L’accessibilité des collections. Pour cela, elles mettent en place des dispositifs visant à rendre accessibles des documents non exploitables informatiquement préalablement (en particulier des fichiers numérisés dans un format image) ou des documents manuscrits qui sont difficiles à traiter par ordinateur.
• L’évolution des processus internes, en particulier des solutions sont déployées à la fois pour mettre en place de la maintenance prédictive (l’objectif étant de savoir quel ouvrage a besoin d’être entretenu/réparé pour assurer sa préservation) ou pour aider à optimiser le rangement et l’organisation des magasins.
La feuille de route évoque à plusieurs reprises Gallica sur lequel nous allons nous attarder plus précisément.
Le cas de Gallica à la BnF
Fer de lance de la BnF pour les questions de l’IA, la bibliothèque numérique Gallica, lancée en 1997 a pour mission de rendre accessibles les ressources patrimoniales de la BnF. Les défis technologiques ont fait prendre à Gallica une importance croissante et en font un terrain d’expérimentation. Ainsi, Jean-Philippe Moreux, expert IA à la BnF, a schématisé de la façon suivante l’évolution de Gallica :
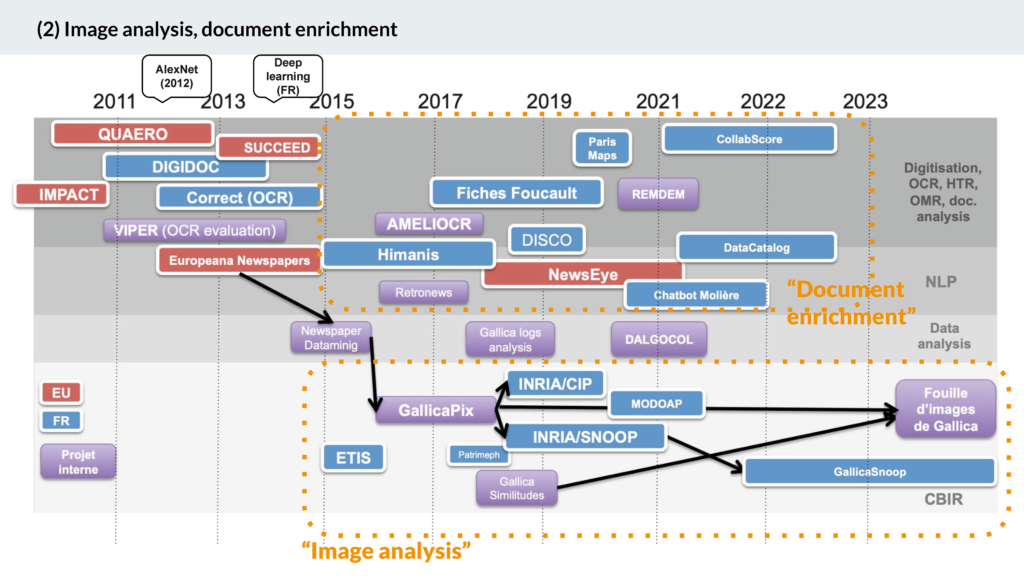
Nous pouvons observer l’importance des collaborations avec des acteurs externes, en particulier dans des contextes de projets européens. Ces échanges sont cruciaux pour la BnF, à la fois pour bénéficier de fonds nécessaires à ses travaux de R&D, mais aussi pour obtenir les compétences clés afin de les mettre en œuvre. Dans son schéma, Jean-Philippe Moreux distingue les projets : ceux centrés sur l’analyse/fouille d’images et ceux consacrés à l’enrichissement des documents (pour favoriser la fouille de données). Les innovations sont progressives même si une difficulté majeure reste l’intégration des prototypes développés (comme GallicaPix) dans le système opérationnel (ici Gallica) et la gestion de la mise à l’échelle de l’outil7. L’objectif de toutes ces expérimentations est de renforcer l’accessibilité des collections nationales et les usages associés.
En parallèle, un travail conjoint est réalisé avec des bibliothèques partenaires qui coopèrent avec la BnF pour mettre en ligne leurs collections à la fois dans leurs espaces et dans Gallica. Ce sont quasiment 300 bibliothèques qui utilisent Gallica en marque blanche à l’image de la Bibliothèque nationale et universitaire (BNU) de Strasbourg qui propose un accès à une bibliothèque numérique Numistral8 basée sur Gallica.
Transformations en cours, quel(s) avenir(s) pour l’IA dans les bibliothèques ?
Les bibliothèques font face à de nombreux défis dans ce contexte. Si l’usage de ces technologies est de plus en plus accepté en interne, les besoins en compétences de pointe explosent. Pour y répondre, ces institutions qui, certes, accueillent de nouveaux métiers en se dotant de structures (comme le dataLab9 de la BnF) en leur sein, reposent principalement sur des partenariats avec des laboratoires de recherche (l’INRIA par exemple) ou des contrats de prestations auprès de sociétés de services ou de conseils.
Dans un contexte de restriction budgétaire, les projets relatifs à l’IA en bibliothèque demandent d’importants financements pour être menés à bien. Si des institutions, comme la BnF, arrivent encore à mobiliser des budgets propres pour certaines expérimentations, pour les industrialiser, les bibliothèques répondent de plus en plus à des appels à projets (notamment européens) ou à des partenariats avec des acteurs privés. Une difficulté rencontrée est celle de l’évaluation des projets d’IA. Peu d’entre elles mettent en œuvre une évaluation des impacts de leurs projets et donc sont capables de justifier les retombées concrètes associées.
Les bibliothèques, dont les missions fondamentales sont de plus en plus concurrencées par des acteurs privés s’inscrivant dans une logique d’extraction de la connaissance et d’accessibilité à celle-ci sont dans le même temps une source précieuse pour les acteurs du numérique. Nous pouvons noter un appétit croissant des géants du numérique pour les données structurées qu’elles produisent10. Leurs grandes quantités de données font de celles-ci une source intéressante pour un acteur qui souhaite entraîner un modèle informatique aussi bien sur du texte que sur des images. Elles sont alors de plus en plus sollicitées – parfois prédatées de manière sauvage lors de la phase d’entraînement des algorithmes11– par des entreprises pour mettre à disposition leurs collections pour l’entraînement d’algorithmes.
Avec la pression croissante des grandes entreprises du numérique, des États, mais aussi des contextes budgétaires contraints, se pose in fine la question de la place des bibliothèques et de leur positionnement dans le monde qui se dessine. De nouveaux espaces se construisent, ainsi la CENL permet à ses membres d’échanger dans un contexte européen. Une série de webinaires est actuellement proposée par l’organisation afin de diffuser le plus largement possible leurs avancées12. En parallèle, des collectifs se construisent comme AI4LAM (intelligence artificielle pour les bibliothèques, archives et musées) qui visent à mettre en relation les acteurs du secteur et à partager les bonnes pratiques, les projets en cours et toutes les questions que peuvent se poser les parties prenantes.
Nous pouvons noter aussi de plus en plus de ressources partagées par les bibliothèques pour s’aider mutuellement dans cet environnement mouvant. Ainsi, par rapport à un enjeu de taille qu’est l’évaluation de la sécurité du dispositif mis en place, la Library of Congress met à disposition sa grille d’évaluation des projets.
Pour résumer, à travers cet article, nous avons pu souligner des usages de technologies « intelligentes » que ce soit par la mise en place d’outils pour de la reconnaissance de caractères, dactylographiés ou manuscrits, de l’aide à l’indexation ou au catalogage, ou plus largement à l’accessibilité des collections. Des utilisations moins visibles sont aussi présentes, comme la maintenance prédictive, pour anticiper quel ouvrage restaurer, mais aussi pour optimiser l’organisation ou le stockage des collections. Ces usages croissants sont favorisés par les injonctions des tutelles politiques de réduire les coûts de fonctionnement de ces administrations publiques. Les bibliothèques se trouvent alors sur une ligne de crête où elles doivent trouver un équilibre entre leur mission fondamentale et les besoins des utilisateurs tout en tenant compte des logiques inhérentes à l’activité commerciale de certains partenaires privés.
Il nous semble alors que les réponses qui sont en train de se construire auront des conséquences importantes pour l’ensemble de l’écosystème (que ce soit les bibliothèques municipales ou associatives, ou encore les CDI) aussi bien en termes de financement qu’en termes de compétences tant pour les professionnels que pour les usagers. En effet, les nouveaux usages qui se développent s’accompagnent d’un besoin de formation et surtout du renforcement d’une littératie informationnelle afin d’avoir une réflexion sur les outils dits d’intelligence artificielle et sur leurs usages.